Save Your Twitter Likes Without Using the API
· February 05, 2023 · scraping ·
 Photo by
Photo by As of February 2023, Twitter's free API is becoming a paid-only API. But the great thing about complex web applications like Twitter is there's always another API you can use: the one your web browser uses every day just to load data within the Twitter website.
Using the API Twitter itself uses may be a bit more cumbersome — no documentation, authentication is hacky, and really only useful for operations with accounts you own — but importantly it's still there, free, and quite powerful.
As one example, I was alarmed to find that between accounts being deleted and the crumbling of Twitter itself a lot of my liked tweets from over the past 10 or so years were disappearing. So I took a look at the API calls Twitter.com makes to load my liked tweets and built a hacky Python script to download them all.
From there, the data is yours to store and use however you'd please. I went a next step and output the tweets as HTML for easier browsing, and to easily host the best tweets for easier sharing. All this is now stored completely separate from Twitter!
Instructions on how to get started are in the code's README but the trickiest part is finding your authentication details. For that, you need to:
- Open up the Network debug console of your web browser and then head to your liked tweets page on Twitter.
- Filter for a request to the 'api.twitter.com' domain, with a path ending in '/Likes' -- this is the request the script uses to page through and find all your likes!
- Find the request headers for this API request. You'll need the following values: Authorization, Cookies, and x-csrf-token.
- Add those values to the script's 'config.json' file and you should be ready to roll!
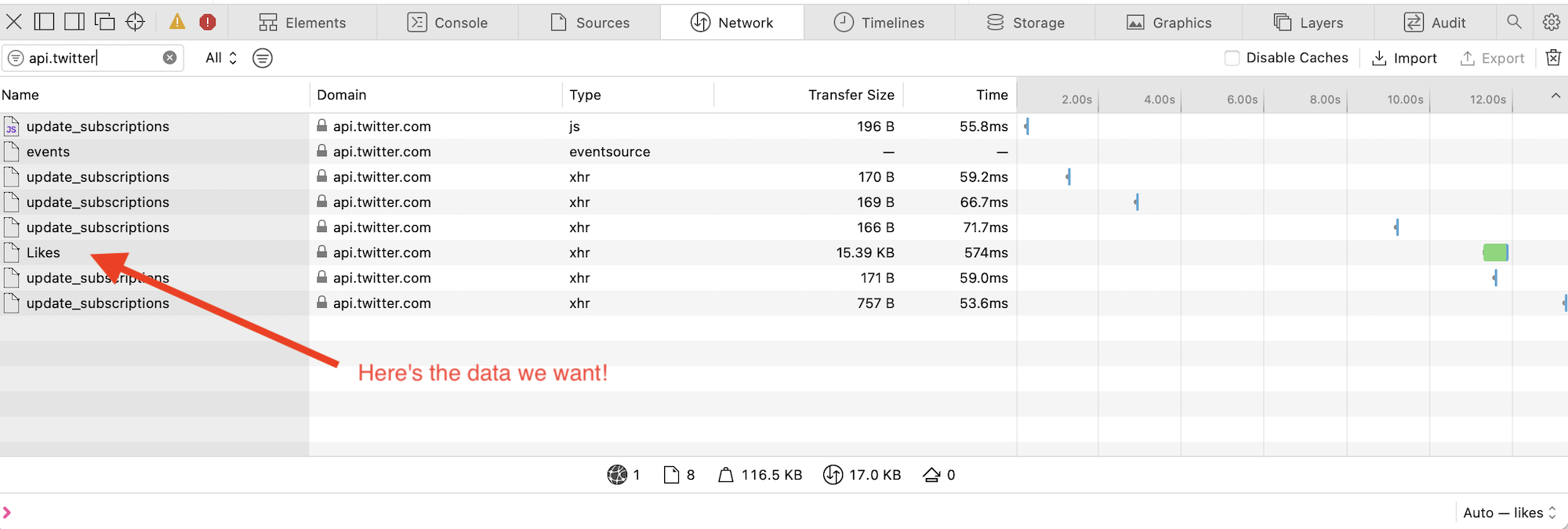
This manual copy-and-paste sleuthing lets you side step Twitter's authentication and just let the script operate as if it were your web browser loading page after page of liked tweets. And it shows you exactly how to expand this starter project into other areas of Twitter: find the requests your web browser makes and replicate them!
It may not be as good as a robust third party API but it's much better than paying a greedy fool.
| Previous | Next |
| Book Report: "The War of the Poor" by Éric Vuillard | Convert a 5K iMac into an External Display |